Using Huginn for profit and fun; finding price errors on the Internet
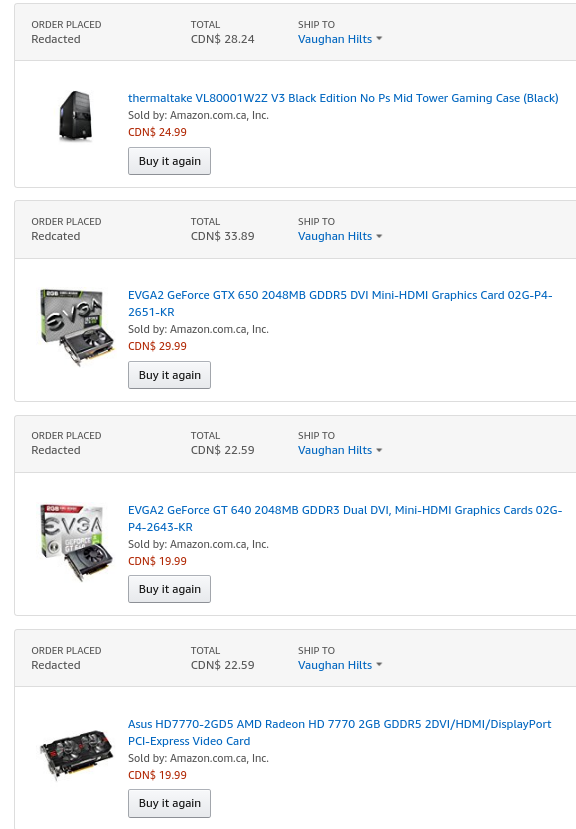
Those are not faked (read: photoshopped) – that is how much I paid for those items sometime in 2014. Those are really good deals for those items, especially in Canadian Dollars. Most of those retailed for about over $100 CAD over here.
These are all known as price error items as the merchant did not intend to sell them for this much. However, sometimes logistics software screws up and there’s a community of people who want to scoop up these things.
They actually come up quite a bit:
- https://www.theguardian.com/money/2014/dec/14/amazon-glitch-prices-penny-repricerexpress
- https://www.google.ca/search?ei=su3kWpLWFKTCjwTJ8JuoBg&q=price+error+redflagdeals&oq=price+error+redflagdeals&gs_l=psy-ab.3…2939.4442.0.4541.0.0.0.0.0.0.0.0..0.0….0…1c.1.64.psy-ab..0.0.0….0.6Tp0J06Cgms
- https://www.telegraph.co.uk/finance/personalfinance/money-saving-tips/11288449/I-spot-and-exploit-pricing-errors-for-a-living.html
.. at least a few times a week in most cases. Of course, not all items are of interest.
The process of ordering something that was priced in error
To get in on this, you need to…
- Notice and find out about the error. Usually communities like RedFlagDeals or SlickDeals have sub-forums where people tell each other about these things. There are also services that notify people (more on this later)
- You need to order and act quick.
You need a quick reaction time as these are often fixed within an hour, sometimes even less than that. There’s other factors as well that affect the quality. In Canada, if you can do in an in-store reservation at that price and then go in to get it the same day – you have better odds than having it shipped, since orders are sometimes canceled on-line but fulfillment rates are high in store.
Since short of reading every thread frequently is tedious, we need automation. Some tools are available already off the shelf to do this which we will dive into first to motivate building something new.
The manual process of finding some of these
Generally, there are a few ways of doing this:
- Subscribe to items on LightningDrops and have them notify you.
- Check communities such as Redflagdeals and then monitor threads
- Keep track of certain items on the individual vendor sites
No single strategy is going to get you 100% of the way there and some services provide automated ways of doing this already for you to increase your chances. I was a frequent user of method #2 for a while but it takes up a lot of time, since often they are the best sources of some of the more obscure deals and involve reading pretty much every thread. Wouldn’t it be nice if we could just get a notification when someone posts something of interest?
Slickdeals has something to do this and so does RedFlagDeals.
I’ve used them. They both have some problems, though:
- They’re a bit slow – it can sometimes take up to 15 minutes to get the e-mail and that’s a bit too slow in some cases (despite saying “instant” on their pages for “Notification Speed”)
- They deliver through their own mechanism, which means e-mail in most cases and perhaps not what we want. Or their application. Or IFTT’s application.
- They don’t support complicated queries or Regular Expressions, which as a developer, I know is pretty important in some cases. ;) We’ll see some example thread titles later that show why this is the case, but image things like HOOOOT or HOTTT!! which are things that won’t be picked up by a basic string matches but something humans might type, with exaggerated letters.
We know the inflexibility problem in this case is because the “data source” and the notification system (and querying of the data) are coupled to each other. We have no way of querying the data ourselves, the communities themselves provide one-stop shops.
Our solution? To decouple the stream of data from the notifications and allow us to create more customized ways of filtering on the data. IFTT is an inspiration for Huginn and kind of solves this problem. IFTT actually has a widget for Slickdeals here but it’s not very customizable. It’s likely you could create your own using IFTT with some work but you won’t be able to get #3 for free that easily and you will have trouble getting 2. IFTT is quite fast, thought.
If you don’t have your own infrastructure, it’s not a bad way to go. But let’s look at alternatives using Huginn to do this. I’m not going to cover the installation, so check out their install guide (I recommend Docker if you can use iti) or my install guide using unRAID if you want to follow along. Otherwise, time to get started.
If you don’t know what Huginn is you can read more about it here. It’s essentially a system that allows you to pull data from various sources, aggregate it into events, query it, and then act on it. That sort of vague, right? But it’s kind of exactly what we need…
Setting up a plan
This is our general plan of attack:
- Monitor the RSS feed of a particular forum and collect new posts only since our last check
- Aggregate them all into a shared pool
- Run some regular expressions against each entry to filter down to the ones we’re interested in as they come in
- Dispatch to a notification daemon and have it notify me in real time if there’s a match
Our notification stack is going to be Pushbullet for a few reasons:
- I already have an account
- It can mirror between phone and desktop, so I’m going to get it quick no matter where I am.
- It supports link types with one click opening of links.
- Huginn has a native agent for it installed by default.
We’ll pull our data from boring Atom RSS feeds – reliable, updated fairly quick and standardized. Huginn also supports web scraping for more speed (since RSS feeds can sometimes lag behind) and for sites that do not provide federated access to their data. We won’t touch this here but it could be pretty easy to implement and swap into.
And in the end, our goal is to look something like this:

in response to something like this:
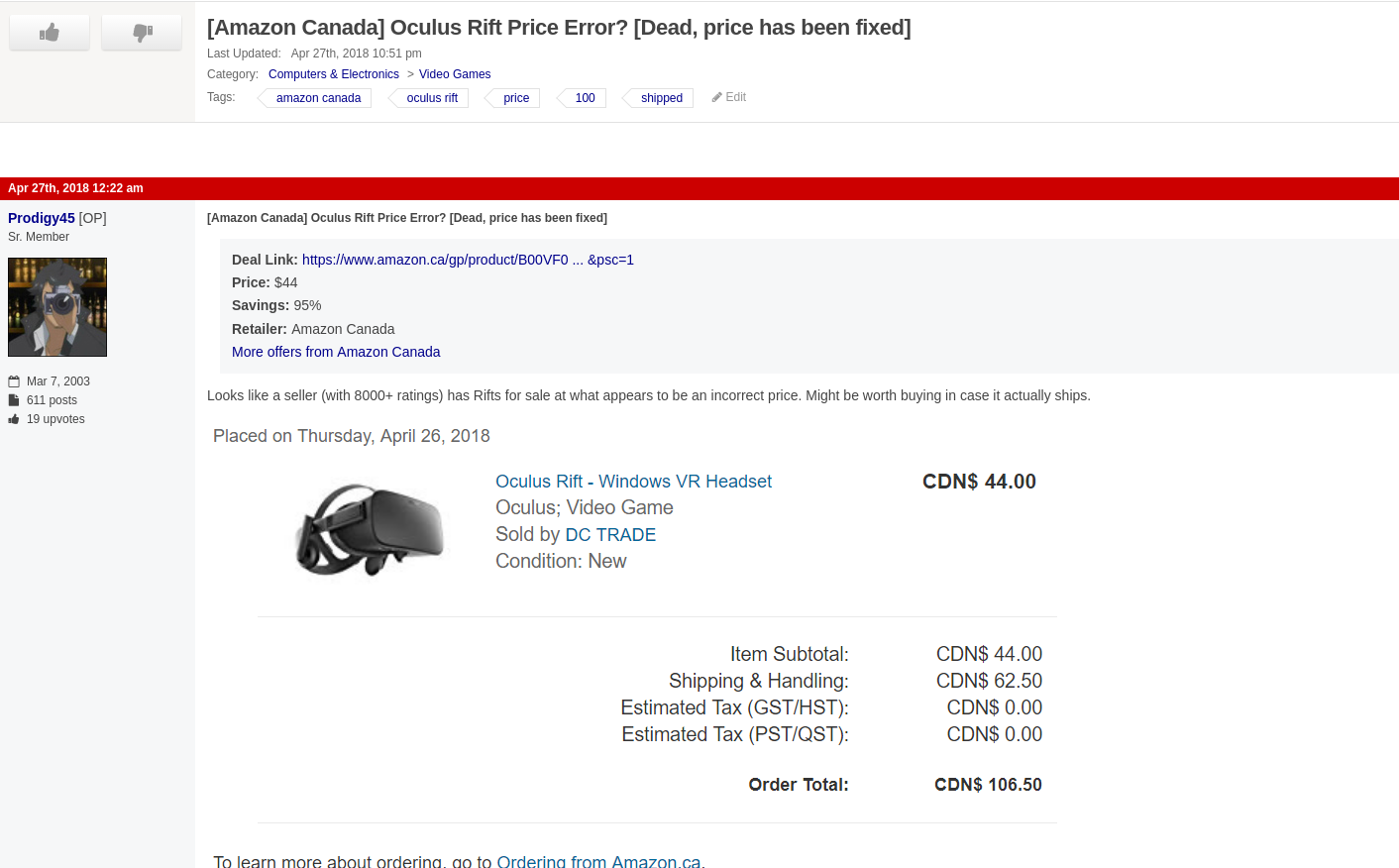
That’s the plan. Let’s figure out how to execute.
A motivation for Huginn
This is all just some basic HTTP requests and data extraction! I can write something working in a couple hours, I don’t need Huginn!
Some Developer before attempting this, probably. (2018)
If you had this reaction, then read the requirements below. Explicit and implicit requirements are dissected and include what complications might arise:
- You need to make sure you only pull new posts – that means you need some kind of in-memory storage at the very minimum and need to write some code to track the ID and only serve up in new ones into a pool. If you want fault tolerance (if your app crashes, you would lose all events) then you might even need something like Redis running in persistent mode. Things just got a bit hairier.
- **If you want to do more than one type of alert, say, SlickDeals afterwards ** … then you need generalized event types. If you need more than one type of notification backend, you need to implement that.
- You need to implement some kind of reliable scheduler, visualizer if you want them This can be
cronbut now you have to managecronjobs. - You need logging of events for debugging.
- You need to integrate with a notification service – this one is bit easier. Most languages have something to do this. For example. here’s one for Node. But you also have to write our own fault tolerance.
- If you want to use this data for other things, you need to make sure you create a generalized abstraction over top to query the data for other purposes.
I mean, it’s not that you can’t write all that but it’s a matter of if you should or need to. Setting this all up can easily take a few hours if you’ve never done it before and even an experienced developer is going to take a bit – and then you have to deploy it. So, that means some kind of deployment technology needed.
Maybe read on first and then come back and see if this is still appealing.
Getting the data into our stream
Huginn uses things called events to pool data into a queue that can be processed by other agents. As a first step, let’s take a look at using this RSS Feed to get out information.
We’ll create a new RSS Agent and set it up like so:
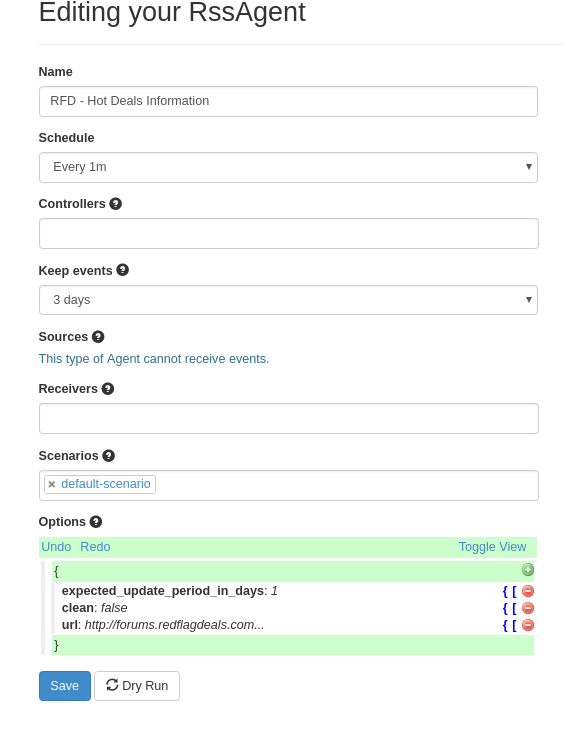
A few explanations in order:
- Scenario: This is just a way of grouping agents together in Huginn. We’re using the default one for now but it would be a good idea to group them later on so you know how they all interact with each other.
- Keep events: We’ve picked 3 days but even less is fine. We’re just using this for triggers which are near real-time, remember. However, if we had other plans for this data more would be in order.
- **Schedule **: 1 minute might be a bit eager, but remember we’d rather generate a bit of extra traffic than miss a deal.
- Expected days: You can read more on the official docs – but this is how Huginn will notify us of broken agents. i.e: we expect data to come in here at least somewhat frequent or something is not right.
With that saved, go ahead and run it and you should generate some activities in the events stream:
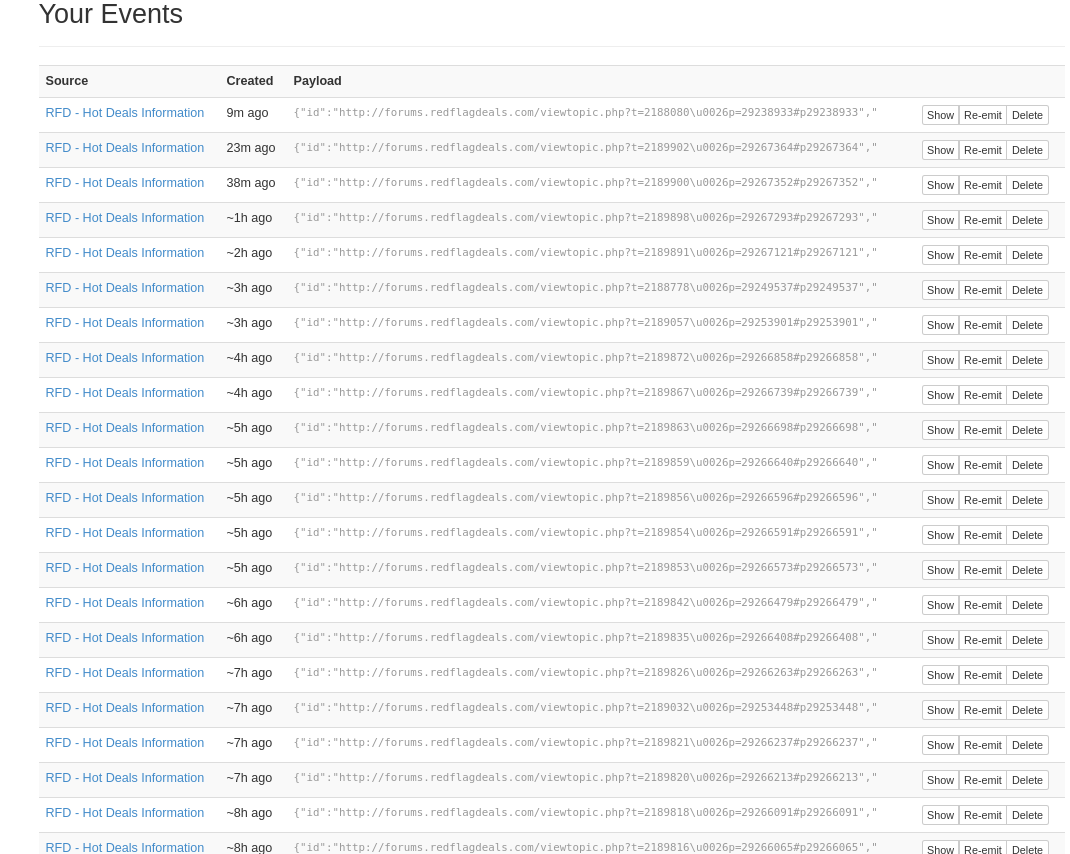
Perfect, we have something that now runs and gets the data and serves it up for us. Let’s get a filter in front of that now.
Filtering the data using regular expressions
We now have our own copy of the data using RSS. It could be through scraping the HTML using the scraper agent, too, though. It does not matter – what does is that we now have events. We don’t want to send every Hot Deal to our devices since that’s just going to result in too many posts. Probably at least three dozen per day, minimum and we don’t want to have to keep checking these.
First, let’s do a little bit of research using Google to figure out what we can expect.
I’ll save you the trouble if you don’t want to search yourself through pages of data and let you know what I came up with:
- The title often contains: price error, price mistake or just the word error.
- The title often contains the word dead if the deal is dead. Or expired
- People sometimes use “HOT” as well when a really good deal is up – sometimes this is not a price error at first but people discover it is later.
- People sometimes exaggerate these words as hinted about before – so just searching for “HOT” as a literal is is likely to miss things, since it may be !!HOOOOT!!! or some variant.
Let’s get a corpus of data going and then try writing some Regular Expressions to match the examples we want. Using a basic script, we can get some of it out:
const cheerio = require('cheerio')
const fs = require('fs')
const data = fs.readFileSync('./file.xml');
const $ = cheerio.load(data, {
xmlMode: false
})
// Get all the title tags
const $titles = $('title')
console.log($titles.first().text());
$titles.each(function (index, titleNode) {
const $titleNode = $(this);
console.log($titleNode.text());
})
(There’s probably a way to do this in Shell as well – but this got me the results in just a few minutes, so good enough)
Our next step is then to write a regular expression that can match as many of the items in the corpus as we can without tripping too many false negatives. Consider the following regular expression below as an example:
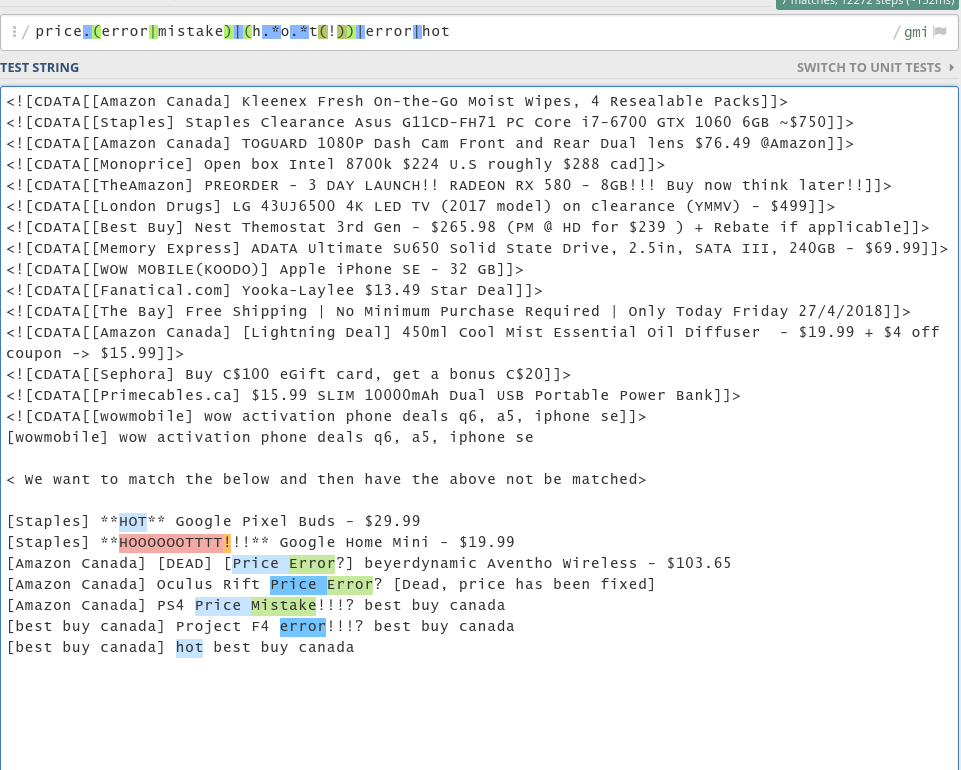
price.(error|mistake)|(h.*o.*t(!))|error|hot/gmi
It covers a few of the cases here without triggering the false positives on the items above. There’s a few items in the list I might personally be interested in (the pre-order for that video card…) but let’s keep our task focused so that we don’t have scope creep.
With this basic regular expression (in practice, I use a slightly more complicated one but this is pretty good) we now have a good basis to filter against. In practice, we could tweak this is a bit more but it gets us a lot of value with low effort (this cruddy regular expression only took 4 minutes to write – yay!)
Creating a new Trigger Agent with the following configuration would give us what we want:
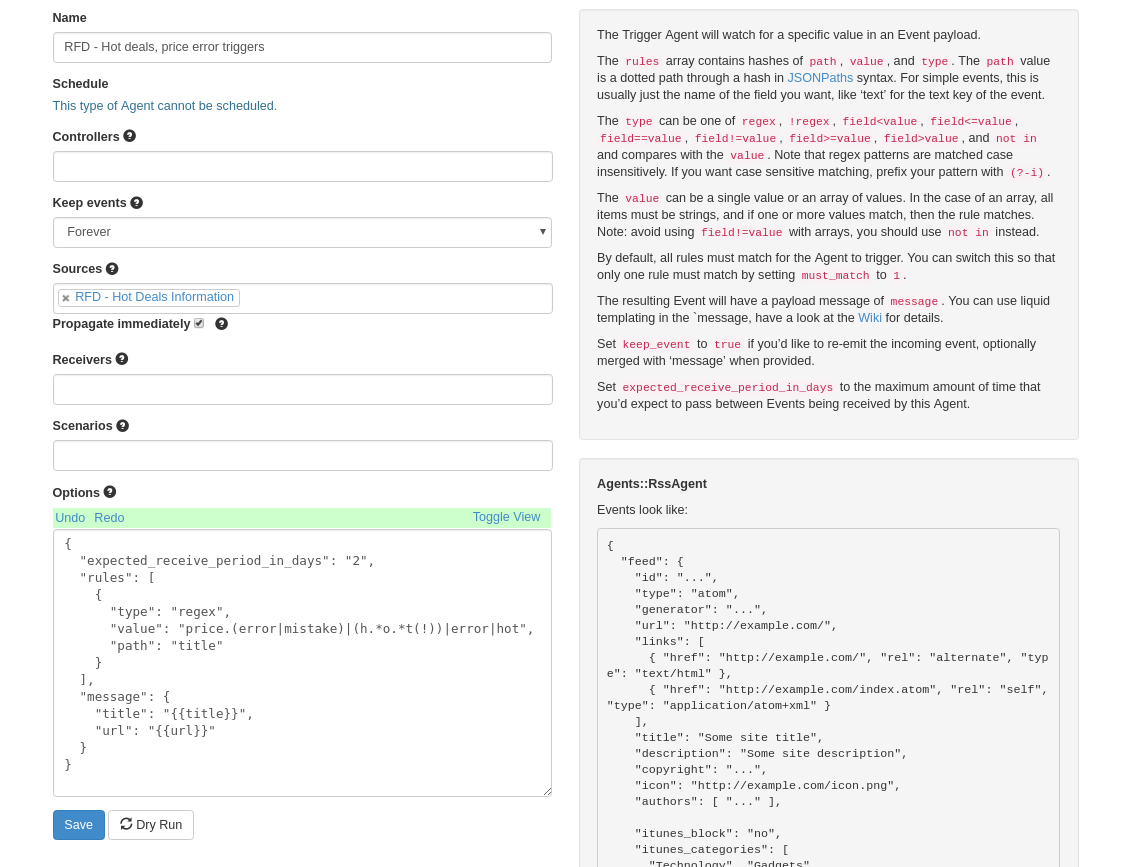
(Trigger Agents allow us to filter data and then generate other events based on these. You can think of the raw data as the base fact and then this is a refinement on those facts. Specifically, it generates additional events we are interested in real time information for. We could still use the raw data for other things since it does not transform it but rather makes a new event for consumption – for example, a daily digest of all the Hot Deals for the day at the end of a day.)
You can use the “Dry Run” functionality to inject some test data to verify it works – but our corpus data should at least give us some confidence. If you wanted to take this to another level, you could have a small toy app that had two test fixtures – valid and invalid and have a script that runs the regex against each test case when modifying it to make sure you don’t have any that are invalid. For now, my regular expression has been running so I have no need to modify it…
Time to get that info into the cloud.
Notifying yourself when it happens
The last part is the easiest part – we just need to get those events we generated into our Pushbullet devices. We can go ahead and create Pushbullet Agent and make sure you get an API key from them.
You can configure it similar to below:
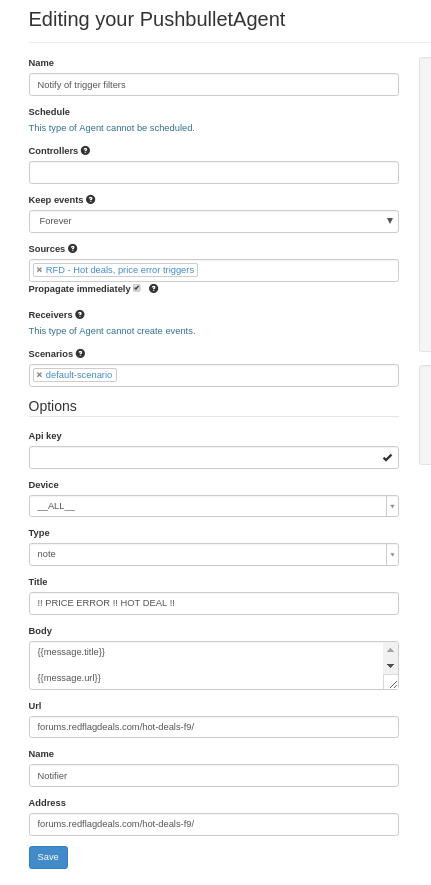
.. and you do need to fill in your API key. After that, you should have everything you need. Since this is a simple dumb relay system, it’s also why I’m comfortable introducing a cloud dependency here. It could easily be swapped for anything else since it lives at the end of the flow.
Profit???
That’s it! With that, we should now have real-time updates to our devices like we showed above. It all works but you don’t have to take my word for it – you can create a manual agent and then trigger some events to watch the entire thing work together. You could also try finding a deal and posting it as well and that would also trigger your new test.
With this, we now have completely automated the process of getting notified of price errors and other interesting deals. I’ve been running a variant of this for a while and scooped up at least a few things such as Google Home Mini’s for $30 to due a coupon error. The original thread title used to say HOT but it was modified since the deal has been expired. It’s not perfect, so I often actually combine this with digests at the end of the day to comb through “not error” things but things I still may be interested in.
Happy savings & hope you learned something!
Got a better idea for a more comprehensive regular expression? Are there better platforms? Just want to say hi? Let me know in the comments.