Scraping the web with X-Ray utilizing Node.js - An example using Google
I recently was working on a project for a client that required going through some
data on the web and extracting some information, known in most circles as data scraping.
Normally when I need to do something like this, I will use Cheerio alongside something like Superagent or just request to download pages and then extract information with a jQuery-like API. This is normally great for dealing with single pages or a list of similar pages that I want to get information from. For example, consider scraping some Wikipedia articles from a known list. Then, we can just run requests to grab the HTML contents and then use Cheerio to pick out what we want. However, I had some extra requirements on this project that made this approach not as straight-forward:
- I needed to be able follow links on pages given some criteria and then easily extract information out from
- I needed to be able to paginate these pages, that is follow a series of links until my results were exhausted
- I needed it to do the heavy lifting for me (Cheerio is purely a DOM-API library) to save time and get the job done.
- I needed rate-limited, which I have built before in the past, but it would be nice if something handled it for me.
That’s where X-Ray comes in – it so happens that
it uses Cheerio and request as dependencies, as well. It’s an abstraction against these
two and makes scraping the web easy. Below, I’m going to illustrate how to scrape Google
search results and follow their links for more information.
—
Setting Up
Getting started is pretty easy, just download the package using npm:
npm install x-ray@2.0.2 --save
And then, inside of your Node.js file just do:
var Xray = require('x-ray')
var x = new Xray()
You’re set!
Why 2.0.2?
At the time writing, there is an open issue for the newer versions (Issue #65) that prevents some of the things we want to do. You should try the later versions if you are reading this in the future.
Querying Google
You can read the syntax on the X-Ray page to get a better idea of what is going on but I will try to explain below, what is going on. First, our goal:
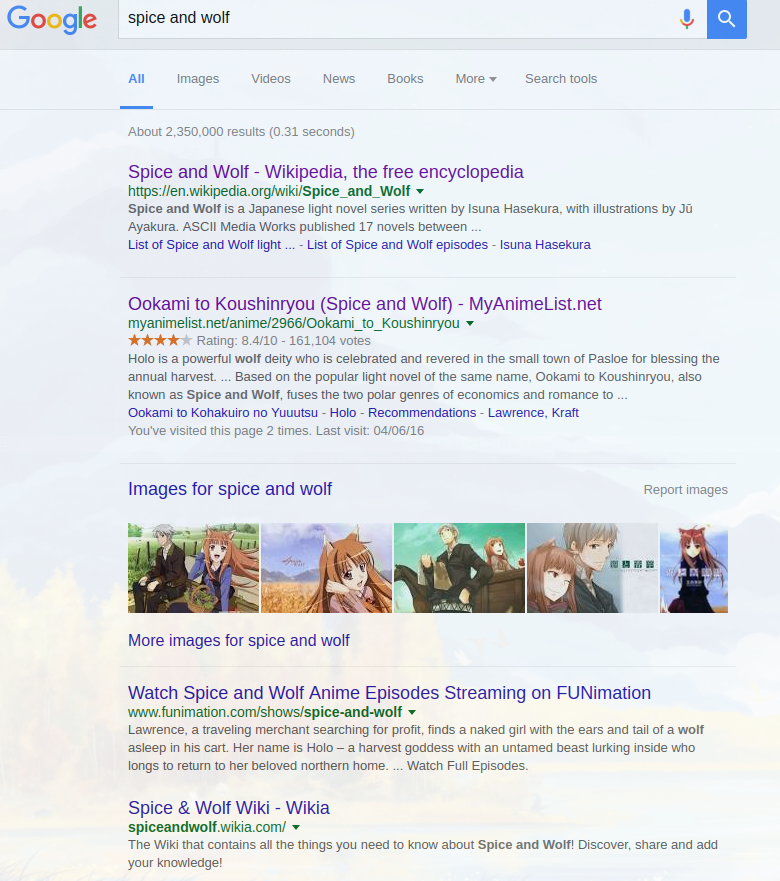
We want to be able to programmatically run a Google Search and extract the URL of each of those links, and then in turn, we want to be able to visit each of them and extract:
- The
titleof the page it links to, after viewing it - The very first link on each page, that is the first
atag and it’shrefattribute
Surprisingly, this is pretty easy to in X-Ray, we can do it like so:
x("https://www.google.ca/search?site=&source=hp&q=spice+and+wolf&oq=spice+and+wolf", '.g', [{
link: 'a@href',
}]).paginate('#pnnext@href').limit(5)
((err, obj) => {
if(err) {
callback(err);
}
else {
obj.forEach((item) => {
var start = item.link.indexOf('q=')
var end = item.link.indexOf('&sa')
item.link = item.link.substring(start + 2, end)
})
callback(null, obj) // do something with the objects?
}
})
A couple interesting observations here:
- There is no explicit request code, no
loador anything l ike that into aCheerioobject. - There are no temporary variables or forming of an object manually, like we may do with
Cheerio - All the error handling code for elements is missing. As it would turn out,
X-Rayhandles this and forwards it to theerrparameter in the callbacks. .paginateis present and so is.limit. These are actually part of the fluent API that is provided to us – we can simply provide a selector to the “clickable next button” on the page and x-ray will internally paginate the results, iterating over the next 5 pages in this case, adding even more results to our internal array.
The 2nd parameter in the x function is just the scope in which selections should be done on. The 3rd is kind of strange – it’s an array of objects wrapped. By wrapping in square brackets, we are instructing X-Ray to iterate once for each .g, without the brackets, it would execute once. So, the flow goes something like this.
Download the page
For each element in the set of .g ...
Extract the first *a* element's href
Return the result
The only annoying portion is the link stripping and that is because of the way Google formatted the links at the time of writing. It’s actually kind of a hack but I am sure there is a better way to extract it out if you want to.
Then, the only step left is to visit the links and process them. As it would turn out, you can compose in X-Ray to make this a snap as well. Consider the following:
x("https://www.google.ca/search?site=&source=hp&q=spice+and+wolf&oq=spice+and+wolf", '.g', [{
link: 'a@href',
details: x('a@href', {
title: 'title',
link: 'a@href',
linkText: 'a@text'
})
}]).paginate('#pnnext@href').limit(5)
((err, obj) => {
if(err) {
callback(err);
}
else {
callback(null, obj) // do something with the objects?
}
})
Notice the new details section? This will execute for each page and extract out:
- The
titletag - The first link location of an
atag - The first link
atag’s text
We’d have to write a lot of boilerplate spaghetti to do this without our framework. So, if we then go ahead and print out of some this using a basic loop, (printing title and link URLs for now), we get something like:
Watch Spice and Wolf Anime Episodes Streaming on FUNimation :::: http://www.funimation.com/loadModal/index/forgot_password_modal
Spice & Wolf Wiki - Wikia :::: http://spiceandwolf.wikia.com/#WikiaArticle
http://www.google.com/ :::: https://www.youtube.com/watch%3Fv%3DI4Ztnt5ej20#
Ookami to Koushinryou (Spice and Wolf) - MyAnimeList.net :::: http://myanimelist.net/
Page not found :::: http://hachettebookgroup.com/
Spice and Wolf (TV) - Anime News Network :::: http://www.animenewsnetwork.com/
Ookami to Koushinryou - Anime - AniDB :::: https://anidb.net/animedb.pl?show=main
Ôkami to kôshinryô (TV Series 2008– ) - IMDb :::: http://pubads.g.doubleclick.net/gampad/...
Cool! We could evidently extract more information from the pages if we needed to. Since we decided to maintain a link on the top-level of each object as well, we could run this through another X-ray parser to fetch site specific data depending on the URL, if we needed to. For example, if we detected a YouTube video / a video site, we might also be interested in, say it’s view count.
Conclusion
So, if you have some requirements that I had – you should definitely check out X-Ray. Specifically, if you need pagination, easy robust requests, rate limiting and a nice execution flow you will get it here. If you want to see an example of this code and chaining requests, you can find it on my Github page.